
Note: The following is a blog post I wrote as part of a paid written work trial with Epoch. For probably obvious reasons, I didn’t end up getting the job, but they said it was okay to publish this.
Historically, one of the major reasons machine learning was able to take off in the past decade was the utilization of Graphical Processing Units (GPUs) to accelerate the process of training and inference dramatically. In particular, Nvidia GPUs have been at the forefront of this trend, as most deep learning libraries such as Tensorflow and PyTorch initially relied quite heavily on implementations that made use of the CUDA framework. The strength of the CUDA ecosystem remains strong, such that Nvidia commands an 80% market share of data center GPUs according to a report by Omdia (https://omdia.tech.informa.com/pr/2021-aug/nvidia-maintains-dominant-position-in-2020-market-for-ai-processors-for-cloud-and-data-center).
Given the importance of hardware acceleration in the timely training and inference of machine learning models, it might be naively seem useful to look at the raw computing power of these devices in terms of FLOPS. However, due to the massively parallel nature of modern deep learning algorithms, it should be noted that it is relatively trivial to scale up model processing by simply adding additional devices, taking advantage of both data and model parallelism. Thus, raw computing power isn’t really a proper limit to consider.
What’s more appropriate is to instead look at the energy efficiency of these devices in terms of performance per watt. In the long run, energy constraints have the potential to be a bottleneck, as power generation requires substantial capital investment. Notably, data centers currently use up about 2% of the U.S. power generation capacity (https://www.energy.gov/eere/buildings/data-centers-and-servers).
For the purposes of simplifying data collection and as a nod to the dominance of Nvidia, let’s look at the energy efficiency trends in Nvidia Tesla GPUs over the past decade. Tesla GPUs are chosen because Nvidia has a policy of not selling their other consumer grade GPUs for data center use.
The data for the following was collected from Wikipedia’s page on Nvidia GPUs (https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units), which summarizes information that is publicly available from Nvidia’s product datasheets on their website. A floating point precision of 32-bits (single precision) is used for determining which FLOPS figures to use.
A more thorough analysis would probably also look at Google TPUs and AMDs lineup of GPUs, as well as Nvidia’s consumer grade GPUs. The analysis provided here can be seen more as a snapshot of the typical GPU most commonly used in today’s data centers.
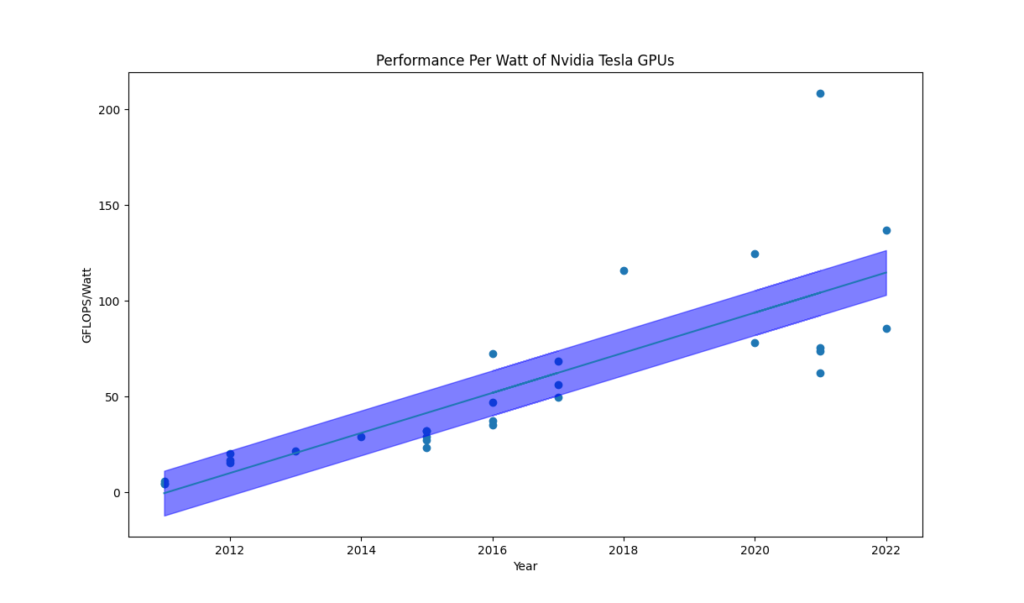
Figure 1: The performance per watt of Nvidia Tesla GPUs from 2011 to 2022, in GigaFLOPS per Watt.
Notably the trend is positive. While wattages of individual cards have increased slightly over time, the performance has increased faster. Interestingly, the efficiency of these cards exceeds the efficiency of the most energy efficient supercomputers as seen in the Green500 for the same year (https://www.top500.org/lists/green500/).
An important consideration in all this is that energy efficiency is believed to have a possible hard physical limit, known as the Laudauer Limit (https://en.wikipedia.org/wiki/Landauer%27s_principle), which is dependent on the nature of entropy and information processing. Although, efforts have been made to develop reversible computation that could, in theory, get around this limit, it is not clear that such technology will ever actually be practical as all proposed forms seem to trade off this energy savings with substantial costs in space and time complexity (https://arxiv.org/abs/1708.08480).
Space complexity costs additional memory storage and time complexity requires additional operations to perform the same effective calculation. Both in practice translate into energy costs, whether it be the matter required to store the additional data, or the opportunity cost in terms of wasted operations.
More generally, it can be argued that useful information processing is efficient because it compresses information, extracting signal from noise, and filtering away irrelevant data. Neural networks for instance, rely on neural units that take in many inputs and generate a single output value that is propagated forward. This efficient aggregation of information is what makes neural networks powerful. Reversible computation in some sense reverses this efficiency, making its practicality, questionable.
Thus, it is perhaps useful to know how close we are to approaching the Laudauer Limit with our existing technology, and when to expect to reach it. The Laudauer Limit works out to 87 TeraFLOPS per watt assuming 32-bit floating point precision at room temperature.
Previous research to that end has proposed Koomey’s Law (https://en.wikipedia.org/wiki/Koomey%27s_law), which began as an expected doubling of energy efficiency every 1.57 years, but has since been revised down to once every 2.6 years. Figure 1 suggests that for Nvidia Tesla GPUs, it’s even slower.
Another interesting reason why energy efficiency may be relevant has to do with the real world benchmark of the human brain, which is believed to have evolved with energy efficiency as a critical constraint. Although the human brain is obviously not designed for general computation, we are able to roughly estimate the number of computations that the brain performs, and its related energy efficiency. Although the error bars on this calculation are significant, the human brain is estimated to perform at about 1 PetaFLOPS while using only 20 watts (https://www.openphilanthropy.org/research/new-report-on-how-much-computational-power-it-takes-to-match-the-human-brain/). This works out to approximately 50 TeraFLOPS per watt. This makes the human brain less powerful strictly speaking than our most powerful supercomputers, but more energy efficient than them by a significant margin.
Note that this is actually within an order of magnitude of the Laudauer Limit. Note also that the human brain is also roughly two and a half orders of magnitude more efficient than the most efficient Nvidia Tesla GPUs as of 2022.
On a grander scope, the question of energy efficiency is also relevant to the question of the ideal long term future. There is a scenario in Utilitarian moral philosophy known as the Utilitronium Shockwave, where the universe is hypothetically converted into the most dense possible computational matter and happiness emulations are run on this hardware to maximize happiness theoretically. This scenario is occasionally conjured up as a challenge against Utilitarian moral philosophy, but it would look very different if the most computationally efficient form of matter already existed in the form of the human brain. In such a case, the ideal future would correspond with an extraordinarily vast number of humans living excellent lives. Thus, if the human brain is in effect at the Laudauer Limit in terms of energy efficiency, and the Laudauer Limit holds against efforts towards reversible computing, we can argue in favour of this desirable human filled future.
In reality, due to entropy, it is energy that ultimately constrains the number of sentient entities that can populate the universe, rather than space, which is much more vast and largely empty. So, energy efficiency would logically be much more critical than density of matter.
This also has implications for population ethics. Assuming that entropy cannot be reversed, and the cost of living and existing requires converting some amount of usable energy into entropy, then there is a hard limit on the number of human beings that can be born into the universe. Thus, more people born at this particular moment in time implies an equivalent reduction of possible people in the future. This creates a tradeoff. People born in the present have potentially vast value in terms of influencing the future, but they will likely live worse lives than those who are born into that probably better future.
Interesting philosophical implications aside, the shrinking gap between GPU efficiency and the human brain sets a potential timeline. Once this gap in efficiency is bridged, it theoretically makes computers as energy efficient as human brains, and it should be possible at that point to emulate a human mind on hardware such that you could essentially have a synthetic human that is as economical as a biological human. This is comparable to the Ems that the economist Robin Hanson describes in his book, The Age of EM. The possibility of duplicating copies of human minds comes with its own economic and social considerations.
So, how long away is this point? Given the trend observed with GPU efficiency growth, it looks like a doubling occurs about every three years. Thus, one can expect an order of magnitude improvement in about thirty years, and two and a half orders of magnitude in seventy-five years. As mentioned, two and a half orders of magnitude is the current distance from existing GPUs and the human brain. Thus, we can roughly anticipate this to be around 2100. We can also expect to reach the Laudauer Limit shortly thereafter.
Most AI safety timelines are much sooner than this however, so it is likely that we will have to deal with aligning AGI before the potential boost that could come from having synthetic human minds or the potential barrier of the Laudauer Limit slowing down AI capabilities development.
In terms of future research considerations, a logical next step would be to look at how quickly the overall power consumption of data centers is increasing and also the current growth rates of electricity production to see to what extent they are sustainable and whether improvements to energy efficiency will be outpaced by demand. If so, that could act to slow the pace of machine learning research that relies on very large models trained on massive amounts of compute. This is in addition to other potential limits, such as the rate of data generation for large language models, which depend on massive datasets of essentially the entire Internet at this point.
The nature of current modern computation is that it is not free. It requires available energy to be expended and converted to entropy. Barring radical new innovations like practical reversible computers, this has the potential to be a long-term limiting factor in the advancement of machine learning technologies that rely heavily on parallel processing accelerators like GPUs.